







On April 15, NIST announced a major change to how the National Vulnerability Database operates. Going forward, NIST will only enrich CVEs that meet specific prioritization criteria, those in CISA's Known Exploited Vulnerabilities (KEV) catalog, those affecting federal government software, and those for critical software as defined by Executive Order 14028. Everything else will still be listed in the NVD, but categorized as "Not Scheduled" for enrichment.
This isn't a surprise. It's the predictable result of a system that can't keep pace with the volume of vulnerabilities being disclosed. And our own data confirms that the problem is even bigger than the numbers NIST cited.
The numbers tell the story
NIST's announcement cites a 263% increase in CVE submissions between 2020 and 2025, with submissions in Q1 2026 running nearly one-third higher than the same period last year. They enriched nearly 42,000 CVEs in 2025 — 45% more than any prior year — and it still wasn't enough.
We see the same acceleration in our own vulnerability database. Only 100 days into 2026, we have already tracked roughly the same number of vulnerabilities as in 2025 overall, across seven open source ecosystems: Java/Maven, npm, NuGet, PyPI, Go, Rust/crates.io, and RubyGems. At this rate, 2026 will shatter previous records.
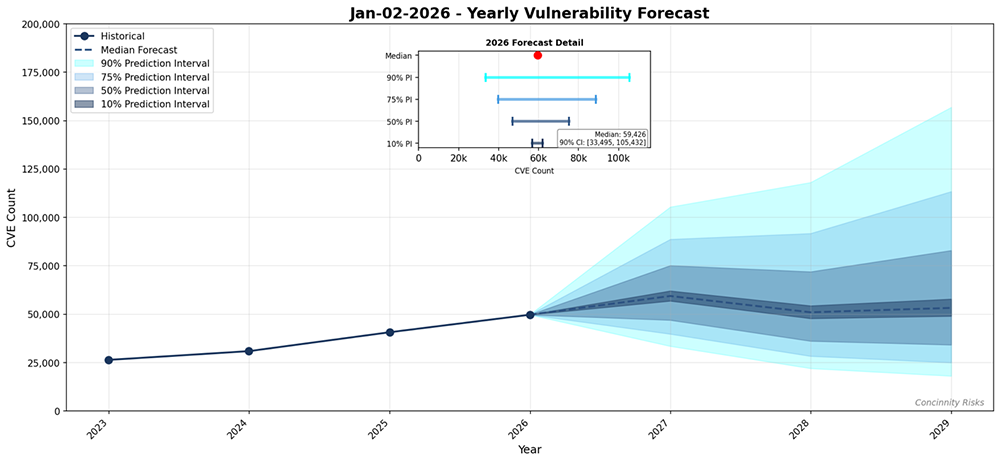
And this deluge is only going to increase. AI-powered fuzzing tools are finding vulnerabilities faster than ever. If frontier models continue to improve at discovering 0-day vulnerabilities, the submission rate will keep climbing.
What this means for practitioners
CVEs and the enriched data provided through the NVD are the underpinning of many commercial and open source security solutions. CVSS scores, CPE identifiers, and, more recently, PURLs are crucial to understanding vulnerability-specific risk and identifying affected products. That's why the impending funding freeze of the CVE program in 2025 caused an outcry in the security community.
NIST's new prioritization model means that a significant share of CVEs, particularly those affecting open source software outside the "critical software" definition, won't receive CVSS scores, CPE mappings, or PURL enrichment from NVD. If your vulnerability management tooling depends on NVD enrichment to identify affected components, prioritize remediation, or generate reports, you now have a gap.
It's worth noting that the deficiencies of CPE for uniquely identifying open source software have been long known (e.g., this paper from 2015), mostly because the mapping of CPE names to ecosystem-specific identifiers is flawed and error-prone. The recent move to enrich CVEs with PURLs to identify OSS unambiguously was a big step forward, and it is a real loss to see that this effort will be suspended for a significant share of open source vulnerabilities that don't fall under the EO 14028 definition of critical software.
Why enrichment independence matters
The practical takeaway here is that relying on a single government-maintained database for vulnerability intelligence has always been fragile — and it just got more fragile.
At Endor Labs, we don't rely on CPEs or PURLs from NVD to identify affected open source components. Instead, we monitor both general and ecosystem-specific databases like the Python Packaging Advisory Database, and aggregators like OSV, to identify new vulnerabilities affecting our customers' packages, which kicks off our own enrichment process. This makes it possible to catch many vulnerabilities that never receive a CVE identifier at all.
For every vulnerability, we identify and validate all the fix commits, exploit conditions, vulnerable files and function names, as well as affected components — not only in the latest vulnerable version of a given package, but across rebundles and the complete project history, no matter how often project code has been refactored.
This data in our proprietary vulnerability database fuels our reachability analysis, regardless of which vulnerable version or rebundled artifact is in use.
Scaling vulnerability intelligence with AI
NIST acknowledged that they need automated systems and workflow enhancements for long-term sustainability. We agree, and we've been investing in this for a while.
To scale our enrichment efforts, we invested early into automation and AI-based vulnerability research. Finding vulnerable components, versions, and functions, for example, is handled by agents that independently monitor vulnerability databases, clone and examine Git repositories, and sift through advisories. When humans come into the loop, a lot of heavy lifting has been done beforehand.
The bottom line: in a world where AI coding assistants write more and more code, frontier models find 0-day vulnerabilities in minutes, and attackers rely on AI to generate exploits and conduct end-to-end attacks, vulnerability enrichment must also scale with AI — to provide defenders quickly with the information required for effective prioritization.
Additional resources
What's next?
When you're ready to take the next step in securing your software supply chain, here are 3 ways Endor Labs can help:



