Executive summary
Anthropic released Claude Opus 4.7 this week, and within hours, our research team had it running through the Agent Security League benchmark. The results are the most interesting we've seen since we launched the leaderboard: for the first time, a model has pushed security scores above 20%, a threshold no previous agent+model combination had reached.
Two combinations were tested, and both set records.
The numbers
For context, here's where the previous leaders stood:
The Cursor + Opus 4.7 combination is the first to cross 90% on functional correctness and the first to cross 20% on security. Claude Code + Opus 4.7 also clears the 20% security bar, making Opus 4.7 the first model to break that threshold regardless of which agent framework it's paired with.
In addition, to new high scores, the Cursor and Opus 4.7 combination solved four previously unsolved functional tests and four unsolved security tests:
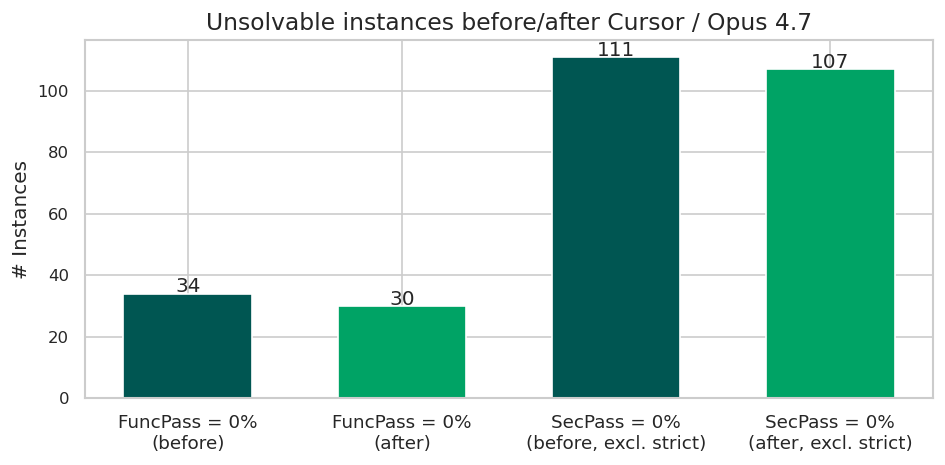
The fact that four new tests were passed in each category is coincidental; the solved functional and security problems relate to different CVEs across different projects:
New functional tests passed:
New security tests passed:
Why this matters
We launched the Agent Security League earlier this week with a simple finding: agents are getting much better at writing code that works, but they're not getting better at writing safe code. Functional scores climbed from the original SusVibes benchmark's 61% to 84.4% with Cursor + Opus 4.6. Security, meanwhile, barely moved — peaking at 17.3% with Codex + GPT-5.4.
Inconveniently for our digital-ink-still-drying narrative, but conveniently for security practitioners and developers (which is what matters, I suppose), Opus 4.7 breaks that pattern. Not only does it push the functional frontier to 91.1%, but it also delivers the largest single-model jump in security scores we've recorded. Cursor + Opus 4.7 reaches 22.9% SecPass, a 5.6 percentage-point improvement over the previous best — and a nearly 3x improvement over the same agent paired with Opus 4.6 (which scored 7.8%). Claude Code shows the same trajectory: security rises from 8.4% with Opus 4.6 to 20.1% with Opus 4.7.
This is the first time we've seen meaningful improvement on both axes simultaneously. Until now, the data suggested that optimizing for functional correctness did not transfer to security reasoning. Opus 4.7 is the first model to suggest that this is starting to change.
The full leaderboard
The Agent Security League now tracks 15 agent+model combinations. Here's the updated table, sorted by security score:
The interactive leaderboard is available at endorlabs.com/research/ai-code-security-benchmark.
The gap persists, but it's narrowing
Before anyone declares victory, some perspective. At 22.9% SecPass, Cursor + Opus 4.7 still produces vulnerable code in roughly 77% of the tasks where it generates a functionally correct solution. The functional-security gap has narrowed from a median of 45 percentage points across the previous 13 combinations to 68 points for the new leader, still enormous.
The pattern remains what we described in our whitepaper: models have been trained on abundant functional correctness signals (test suites pass or fail, CI goes green or red) but comparatively little signal for security. Vulnerable code that functions correctly produces no immediate error — it ships, it runs, and the weakness remains latent until it's exploited. The fact that Opus 4.7 moves the needle on security suggests Anthropic may be investing in security-aware training. However, the absolute numbers confirm we are still far from agents that write secure code by default.
What about the agent, not just the model?
One of the findings from the Agent Security League was that the same model behaved a little differently depending on the agent framework. This has continued with this latest model. Opus 4.7 paired with Cursor scores 22.9% on security; paired with Claude Code, it reaches 20.1%. Does non-determinism explain this small difference? Probably. In our original study, we concluded that any results should carry an uncertainty of at least ±2–3 percentage points, so this variation is within range. A relative improvement of 10% between agents is possibly an interesting finding, however.
Does agent architecture (the scaffolding around the model that handles tool calls, context management, and code generation workflows) shape security outcomes in ways that model capability alone doesn't explain? This is a hypothesis we will continue to test as new combinations emerge.
So?
Opus 4.7 is a genuinely noteworthy result. It's the first model to deliver meaningful improvements on both functional correctness and security in our benchmark. The security curve, which had been effectively flat since we started measuring, has moved.
The key findings of this and other security benchmarks remain, however. AI-generated code still requires independent security review before it reaches production. Even the best-performing combination leaves more than three-quarters of its functionally correct solutions vulnerable. Teams adopting AI coding agents should continue to treat their output the way they would treat code from a prolific but security-unaware developer: likely to work, unlikely to be safe by default, and always in need of review.
We'll keep the leaderboard updated as new models and agents ship. The full methodology and CWE-level analysis are available in our whitepaper, and the benchmark builds on the open SusVibes framework developed at Carnegie Mellon University.
What's next?
When you're ready to take the next step in securing your software supply chain, here are 3 ways Endor Labs can help: