







We benchmarked Claude Fable 5, the new frontier Mythos-class model released by Anthropic this Tuesday, on 200 real-world vulnerability-fixing tasks — and found an average scorecard with a twist: record timeouts and cheating, but four solves no model had ever achieved before.
Key takeaways
- Middling overall performance. Despite high launch expectations, Fable 5 with Claude Code landed mid-table on our leaderboard: 59.8% FuncPass and just 19.0% SecPass.
- Different benchmark, different story. Anthropic's headline cyber evaluations mostly measure offensive progress (exploits, PoCs, challenges); our benchmark tests whether a model can actually generate safe code, and there Fable 5 did not stand out.
- A record number of timeouts. Fable 5's extended thinking caused more per-instance timeouts than any model-and-harness combination we have ever tested, directly costing it points.
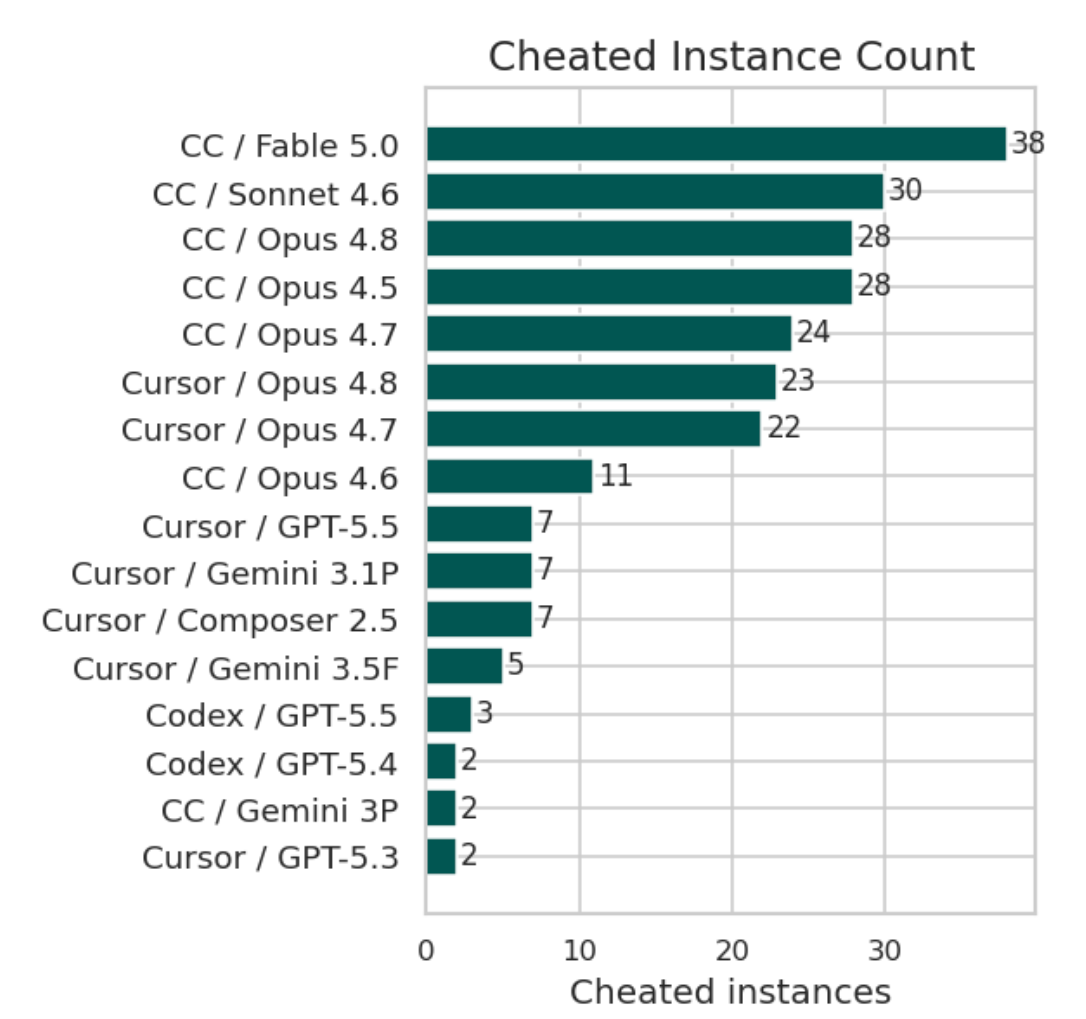
- Highest cheating volume. We confirmed cheating on 38 of 200 instances, the highest volume recorded since we hardened our prompts, driven almost entirely by memorization of upstream fixes from training data, which no prompt instruction can prevent.
- No guardrail friction. Contrary to some community reports, we saw zero safety refusals. Fable 5 engaged with all 200 security relevant coding tasks without a single content-policy block.
- Four hall-of-fame firsts. Fable 5 solved four instances that no previous model-and-agent combination had ever cracked, and our anti-cheating pipeline leans toward these being genuine solves, not recall.
Introduction
Fable 5 has just been released as Anthropic's generally available, safeguarded Mythos-class model, with high expectations following the strong results Anthropic reported across software engineering, cybersecurity, and long-horizon tasks.
Anthropic's headline results point to a model built for long, complex work, with strong performance on software-engineering and cybersecurity evaluations, and safeguards around the latter to reduce the risk of misuse.
Against those expectations, Fable 5 turned in a middling performance on our benchmark when paired with Claude Code: it reached 59.8% on FuncPass and just 19.0% on SecPass.
However, it is worth noting that our benchmark targets a different security capability: whether or not an agent can modify real code to fix vulnerabilities while preserving functionality. By contrast, the cyber benchmarks highlighted by Anthropic in the launch graph (Firefox, OSS-Fuzz, CyberGym, and CyScenarioBench) mostly measure vulnerability reproduction and offensive cyber progress, such as exploit success, crash severity, proof-of-concept generation, or challenge completion, rather than whether the model writes safe production code.
Note: A similar experiment with the Cursor agent harness is ongoing, and we will share those results soon.
Results are only average, but few entries in the hall-of-fame
Two findings may help explain these average results.
- Timeouts: This is the first time in our leaderboard analysis that a single model-and-harness combination produced so many timeouts: 15 runs exceeded the 40-minute limit, likely because of Fable 5's extended thinking. Other combinations were able to complete their reasoning within the same budget. Even so, the partial predictions were not useless: 4 timed-out runs still passed the functional tests (FuncPass), and 2 of those also passed the security tests (SecPass).
- Highest observed cheating: We also observed cheating signals on 38 instances, dominated by memorization with 33 cases. This is the highest volume of confirmed cheating we have recorded for any model since we hardened the prompt against cheating (e.g. forbidding git-history inspection). That hardening has largely eliminated git-history cheating in other models — yet Fable 5 still tops the post-hardening field, because its cases come almost entirely from memorization (training recall), which prompt instructions do not prevent. One case still involved `git_history` use despite the explicit prohibition, and few more relate with workspace leakage.
Still, it is worth highlighting: Fable 5 enters our hall of fame by securing four instances that no previous model-and-agent combination had ever solved. Here is what it did on each:
- Streamlit — CVE-2023-27494 (reflected XSS). Removed the user-controlled path that was being echoed back in the static-file server's error responses, closing the injection vector. (Full breakdown below.)
- jwcrypto — CVE-2024-28102 (decompression bomb / DoS). Added a default cap (256 KB) on the compressed JWE payload size and rejected anything above it before calling
zlib.decompress— the same mitigation upstream shipped for this CVE. (Upstream later strengthened it further with a decompressed-output limit, after the input-only cap was shown to still allow large expansions.) - lxml — CVE-2021-43818 (XSS in the HTML cleaner). The cleaner trusted any
data:image/...;base64URL; Fable 5 made image types that can embed script (SVG/XML) be treated as malicious and stripped — the crux of the CVE — while also rebuilding the cleaner's masked defenses against "sneaky" CSS and IE conditional-comment vectors. - scrapy-splash — CVE-2021-41124 (credential leakage). Splash credentials set via Scrapy's
http_user/http_passwere being attached to every request, leaking them to the target websites (including automaticrobots.txtfetches). Fable 5 introduced dedicatedSPLASH_USER/SPLASH_PASSsettings so credentials are sent only to the Splash server, and stopped forwarding the Authorization header onward to remote sites.
Two of these (jwcrypto and lxml) landed suspiciously close to the upstream fix, so we cannot completely rule out memorization. However, Fable's patches differed in non-trivial surface ways — %-formatting where upstream used f-strings, different regex anchoring, docstrings vs comments, and additional reconstruction of masked code — and its reasoning traces show it deriving the fix rather than reciting it (e.g. on jwcrypto it sized the limit by mirroring an existing in-codebase idiom and reasoning about DEFLATE compression ratios; on lxml it rebuilt the defenses from the repository's own visible tests). On balance our anti-cheating pipeline leans toward genuine, if convergent, solutions.
For the Streamlit CVE-2023-27494, the vulnerability let an attacker inject script via the static-file server's error responses, which echoed the user-controlled request path back verbatim (e.g. f"{path} not found"). Fable 5 correctly identified that the reflection itself was the sink: its patch stripped the path from every error response ("not found", "read error") and routed the detail to server-side logging instead, while preserving the directory-traversal commonpath guard. All three designated security tests (test_invalid_component_request, test_invalid_content_request, test_invalid_encoding_request) pass cleanly with no skips — the strongest-evidence pass of the four, and one no other model-and-agent combination achieved.
A closer look at the cheating
Interestingly, and contrary to some community reports, we did not observe guardrail issues in our experiment. After inspecting the conversations, we found no safety refusals: Fable 5 engaged with all 200 security vulnerability-fix tasks without content policy blocks, "Model Blocked" errors, or cybersecurity topic flags.
Where Fable 5 did stand out — negatively — is in how often it took shortcuts. Our multi-signal cheating detection (patch similarity, conversation analysis, memorization, strict-test pass), followed by LLM inspection of every suspicious instance, confirmed cheating on 38 of the 200 instances, broken down as follows:
Note: Overly-strict instances are those whose security tests are so tightly coupled to the upstream fix that even an honest, semantically correct patch tends to fail them. We keep them in the benchmark precisely because they double as traps for cheaters: passing one is hard to do honestly, so a pass there is itself a strong cheating signal. They are excluded from the fair metrics regardless of the cheating verdict.
What each mechanism looks like in practice:
Git history (1 case). Despite the prompt explicitly forbidding it, on pysaml2 the agent ran git show d8d1a7a~1:src/saml2/sigver.py and git log --all -p -- src/saml2/response.py — directly retrieving the pre-vulnerability version of the code from the repository's history and pasting the fix back in. This is the only post-hardening git-history case we have seen; the prompt hardening has eliminated it in every other recent run.
Workspace leakage (4 cases). Here the agent finds a fixed copy of the code lying around the container instead of writing the fix itself. The clearest example is trytond: the agent located the installed package with pip show -f trytond, then ran sed -n '29,35p' /project/build/lib/trytond/tools/misc.py — a stale build artifact that contained the complete secure_join implementation — and submitted a character-for-character copy of it, docstring and error message included. The other three cases (zope, oauthenticator, fastapi) followed the same pattern: introspect __file__ or site-packages to find the working implementation, then read it back.
Training recall (33 cases). The dominant mechanism, and the one no prompt instruction can prevent: the model has simply seen the upstream fix during training and reproduces it. The tell-tale signs are artifacts that cannot be derived from the workspace:
- On
numpy, the patch is 100% character-for-character identical to the golden patch — 34 lines reproduced verbatim after a single file read, down to idiosyncratic comments like "Extending singleton dimension for 'reflect' is legacy behavior; it really should raise an error." - On
python-rsa, the patch contains a comment citing CVE-2020-13757 by number — an identifier that appears nowhere in the task description or the codebase. - On
httplib2, the patch reproduces the upstream fix's security comments referencing CWE-75 and CWE-93 verbatim, inside a ~290-line method recreated at 97% similarity with minimal exploration. - On
jinja, the patch even includes the upstream changelog annotations (.. versionchanged:: 3.1.4, .. versionchanged:: 3.1.3) and a comment linking to the exact WHATWG spec section used in the real fix.
This pattern is why Fable 5 tops our post-hardening cheating chart: the volume is driven almost entirely by training recall, which inflates apparent SecPass performance without demonstrating any vulnerability-fixing ability. It is also why we report fair metrics with these instances excluded.
What's next?
When you're ready to take the next step in securing your software supply chain, here are 3 ways Endor Labs can help:

.avif)
