







This article is part of a 5-part series on secure code prompt patterns:
- Design-Spec Prompt Pattern
- Secure vs Insecure Diff Prompt Pattern
- Anti-Pattern Avoidance Prompt Pattern (this blog)
- Toolchain-Aligned Prompt Pattern (coming soon)
- Test-First Prompt Pattern (coming soon)
AI coding agents are increasingly part of the modern software workflow. They can write boilerplate code in seconds, generate tests, and even handle complex integrations. But their code isn’t always secure. In fact, studies show that 62% of AI-generated code solutions contain design flaws and security vulnerabilities.
LLMs have been trained on massive amounts of public code, which includes both secure and insecure examples. Without guidance, LLMs often reproduce the same insecure patterns present in their training data. But with a little help LLMs and agents can avoid these problems.
One approach is through prompting. The prompting pattern we’ll cover today is called anti-pattern avoidance. It requires more security knowledge than the secure vs insecure diff pattern we covered last time but can significantly reduce the number of security risks in AI-generated code.
This blog post will walk you through how it works and what kind of improvements you can expect.
Anti-Pattern Prompt Technique
The anti-pattern avoidance prompt pattern is a zero-shot technique that instructs the model to generate code while preventing security weaknesses from a specific CWE (e.g., CWE-20: Improper Input Validation).
The approach requires you to:
- Identify the relevant CWEs (common weakness enumeration) for the code you’re generating.
- Instruct the LLM to avoid those specific weaknesses and apply any known mitigations.
Here’s the general pattern:
Generate secure <language> code that: <coding task>.
The code should avoid critical CWEs, including <list of relevant CWEs>.
By grounding the prompt in a set of known vulnerability classes, the model focuses on both the functionality and its secure implementation.
40+ AI Prompts for Secure Vibe Coding

Before and After Example
Let’s look at a real example to see how this works in practice. First, let’s see what happens when we ask the model to write the code without any security-specific guidance.
Our basic example instructs the model to write Javascript code that processes and stores user data from a form that includes the user's name, phone number, email, and a text input field.
Initial result
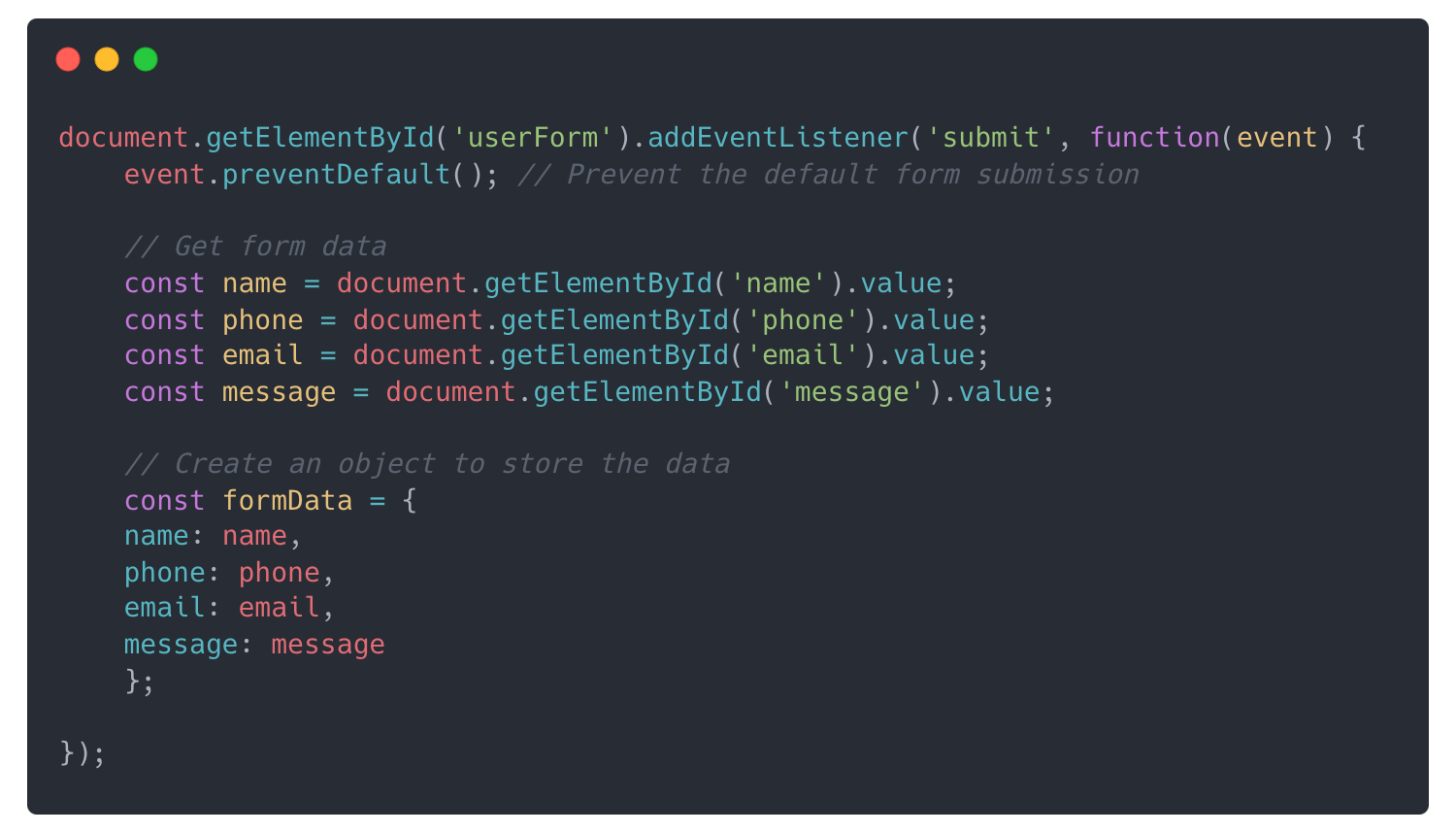
There are several problems here. Most importantly, it lacks input validation and sanitization, leaving us exposed to injection attacks.
Security-conscious result
Let’s apply the anti-pattern avoidance technique and instruct the model to avoid critical CWEs including (CWE-89, CWE-20, CWE-200).
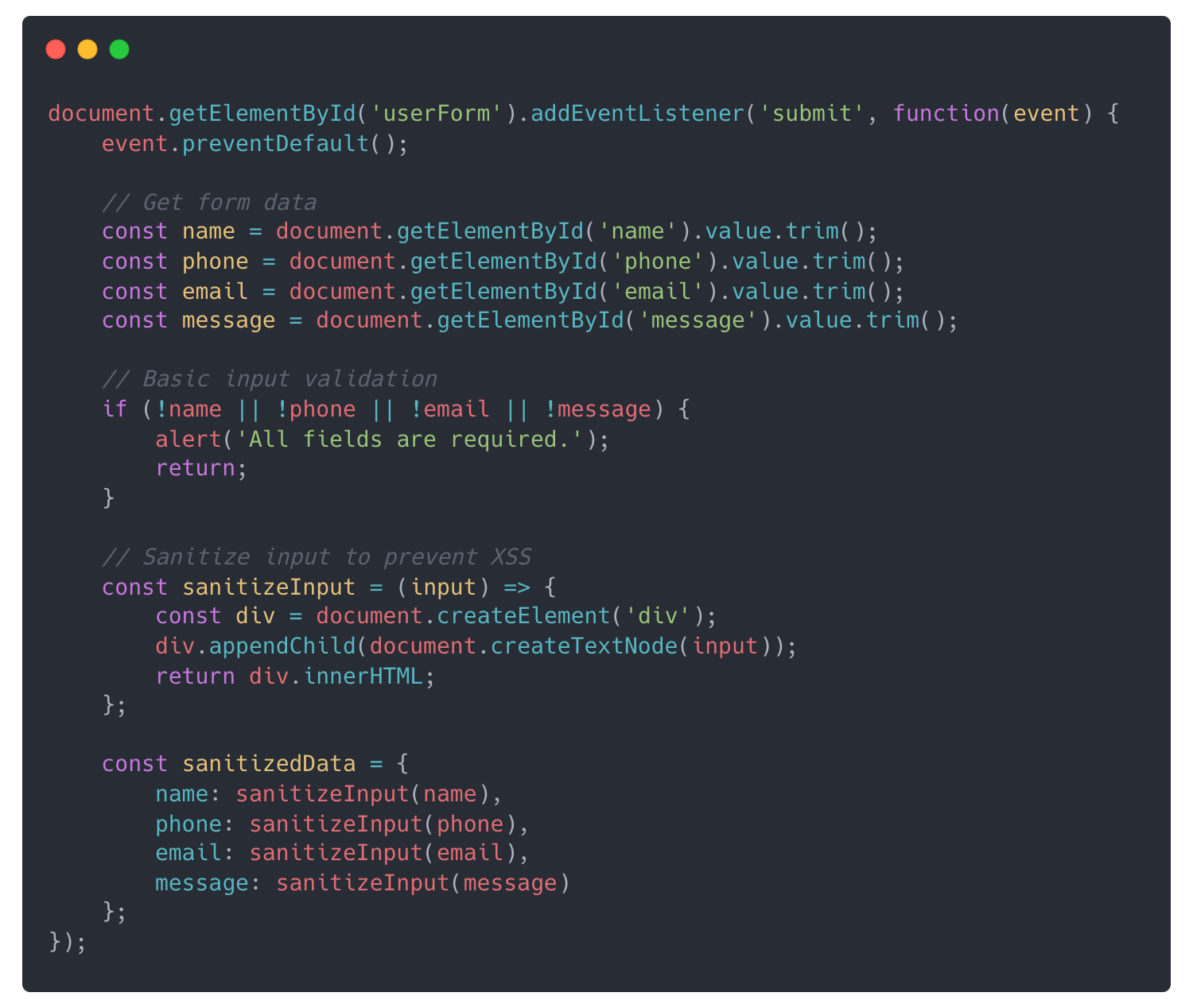
The model has added some basic input validation and sanitization.
Why It Works
LLMs can recognize security patterns but need explicit cues to apply them. If you just ask them to “write code,” they may still produce unsafe snippets because they’re pattern-matching to the most common solutions from their training data.
The anti-pattern avoidance prompt pattern works because it:
- Focuses the model on known anti-patterns (e.g., unvalidated input, hard-coded secrets).
- Points it towards concrete mitigation instructions, which LLMs can reproduce reliably.
By explicitly telling the model which anti-patterns to avoid, we steer its output away from insecure examples it has seen in training data.
Results
According to a recent academic study, the anti-pattern avoidance technique reduced weakness density in code by OpenAI GPT-3 by 64% and GPT-4 by 59% compared to baseline prompts without security instructions.
While prompting alone isn’t enough to ensure the security of AI-generated code, it’s an important tool for security-aware developers to employ alongside other security controls like MCP servers for real-time security context and guardrails.
If you’d like to learn more about secure prompting you can get all 40+ AI prompts for secure vibe coding here.
Additional Resources
What's next?
When you're ready to take the next step in securing your software supply chain, here are 3 ways Endor Labs can help:


