







This article is part of a 5-part series on secure code prompt patterns.
- Design-Spec Prompt Pattern
- Secure vs Insecure Diff Prompt Pattern (this blog)
- Anti-Pattern Avoidance Prompt Pattern
- Toolchain-Aligned Prompt Pattern (coming soon)
- Test-First Prompt Pattern (coming soon)
Studies show that 62% of AI-generated code solutions contain design flaws and security vulnerabilities, issues like hardcoded passwords, missing input validation, and a lack of authentication or access controls.
Fortunately, there’s a lightweight way to guide LLMs towards more secure outcomes from the start. It’s a prompting pattern called Recursive Criticism and Improvement (RCI), or as we like to call it, the secure-insecure diff. In essence, it gets the AI to audit and improve its own code, exposing the “diff” between insecure and secure outputs.
This blog post will walk you through how it works, what kind of improvements you can expect, and when to use it.
Secure-Insecure Diff Prompt Technique
This approach turns the model into its own reviewer by chaining multiple prompts into a workflow:
- Initial generation: “Write secure code for the following task…”
- Critique: “Review your code and identify any security issues.”
- Improve: “Based on your critique, revise and improve the code.”
The result is a before-and-after snapshot: the insecure baseline and a refined, more secure version. For a more robust approach, you can switch between models by for example asking ChatGPT to generate the code and Gemini to review it.
Before and After Example
Let’s say you ask the model to write a Python script that takes a hostname as input and pings it 4 times. The first version will generate a script that does exactly that:
Initial Code:
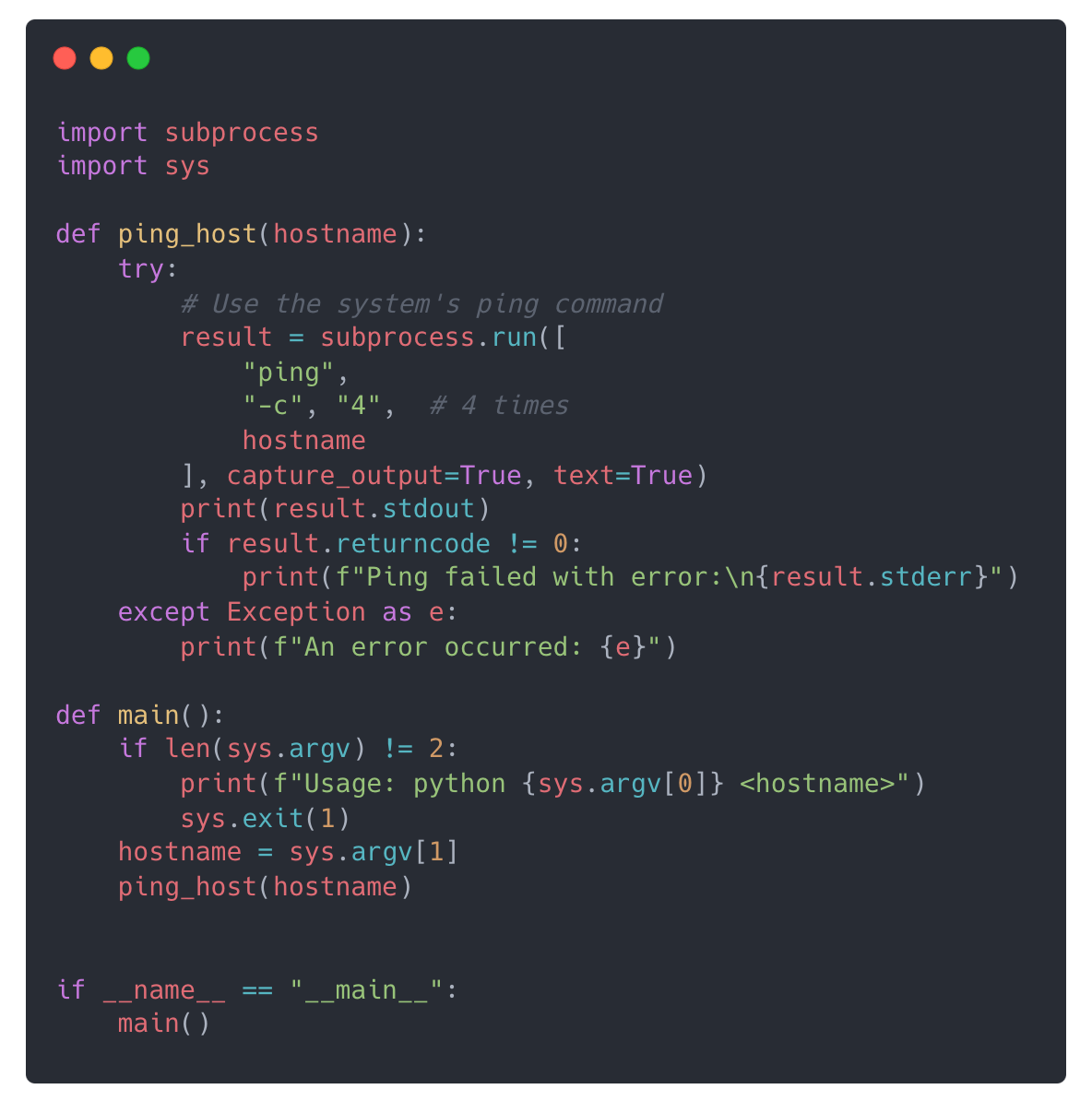
But note that it is missing any kind of input validation to make sure I only receive valid hostnames or IP addresses. Missing input validation is a common security flaw that could be exploited.
Once we ask the model to critique the code we might get something that looks like this:
Improved Code:
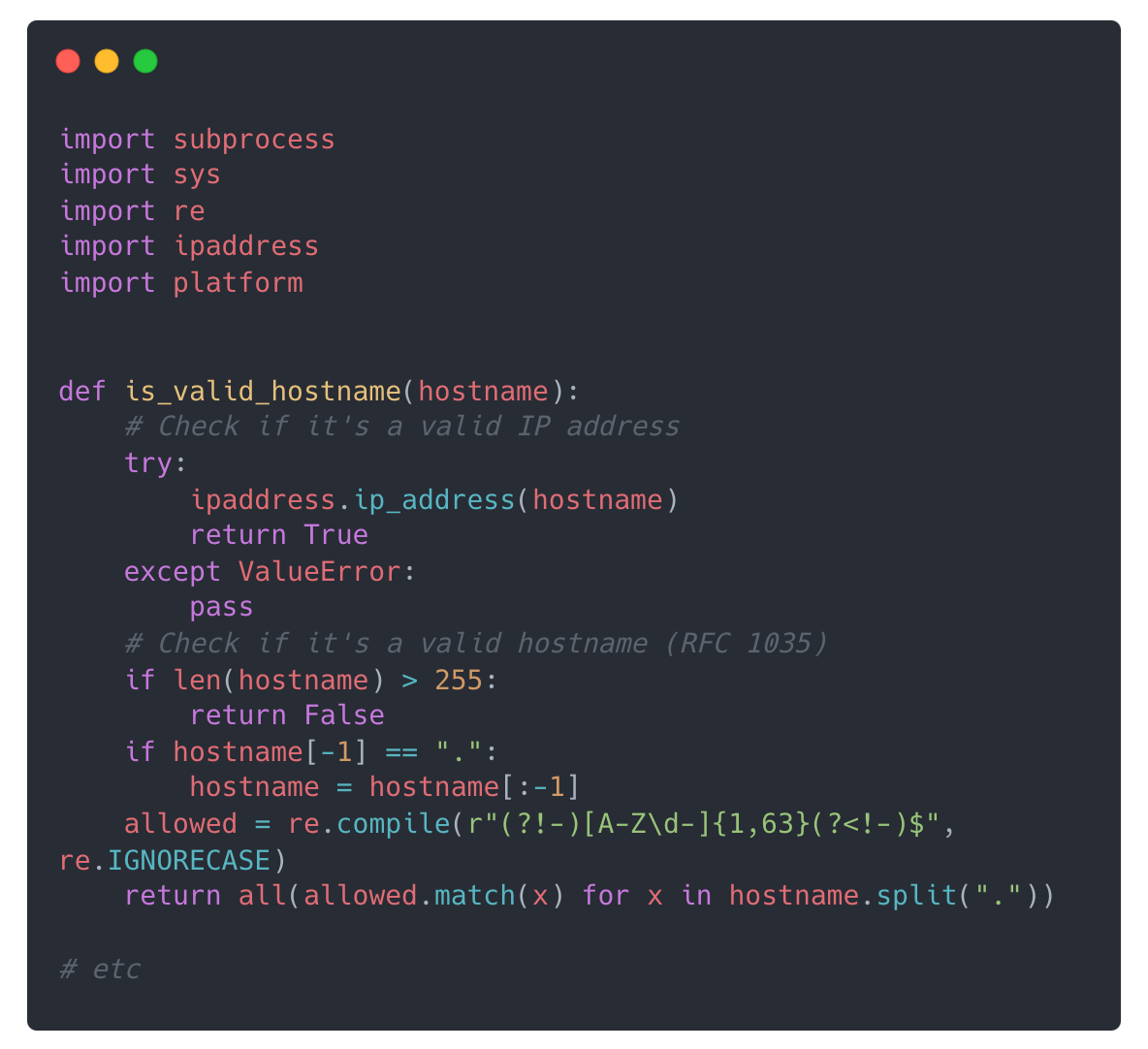
There’s a few changes, but critically, it has added some simple logic to validate the input to make sure we only accept valid hostnames as input.
Why It Works
Most LLMs are better at reviewing than they are at generating secure code from scratch. That’s because:
- They are trained on thousands of examples of insecure patterns from open source code.
- They can reason about flaws once the code exists and is part of their context.
- They excel at incremental improvement when given a clear target.
The RCI method harnesses these strengths. Instead of hoping the model gets it right the first time, it asks the model to identify and fix its own flaws as it works.
The method is most effective when you are generating new functions that interact with user input, the filesystem, subprocesses, or authentication logic. It also doesn’t require the user to have extensive security knowledge to anticipate security issues up front. Research has shown that it can be especially valuable when writing Python or C code, where injection risks and memory issues are common.
Results
According to a recent study the RCI technique reduced the density of security weaknesses in generated Python code by 77.5% compared to baseline prompts with no security cues. That’s a major improvement!
If you're generating code with an LLM and care about security, try prompting it to review and revise its own output. The secure-insecure diff, powered by recursive critique, is one of the simplest and most effective ways to catch vulnerabilities early.
Get 40+ AI prompts for secure vibe coding here.
Additional Resources
What's next?
When you're ready to take the next step in securing your software supply chain, here are 3 ways Endor Labs can help:



