







As companies increasingly embrace artificial intelligence, a new class of software is emerging: AI-native applications. These applications are built from the ground up to leverage the capabilities of large language models (LLMs) and other AI technologies. Unlike traditional applications built on fixed rules, AI-native apps learn from vast datasets and respond dynamically to user inputs.
What is a prompt injection attack?
Prompt injection occurs when an attacker manipulates a language model’s input to trigger unintended, harmful, or insecure outputs. This could allow attackers to bypass security measures, generate malicious code, or affect the model's behavior in harmful ways.
Prompt injection is a significant risk in GenAI applications and tops the OWASP LLM Top 10 for 2025 list. Attackers exploiting prompt injection can compromise the integrity of systems relying on LLMs, highlighting the importance of securing input handling and implementing safeguards against such attacks.
Example: prompt injection introduced in a Python application
A developer has written an internal application that generates summaries for support tickets. The developer knows internal_notes might contain sensitive data, so they strip out secrets and redact fields before sending it to the LLM.
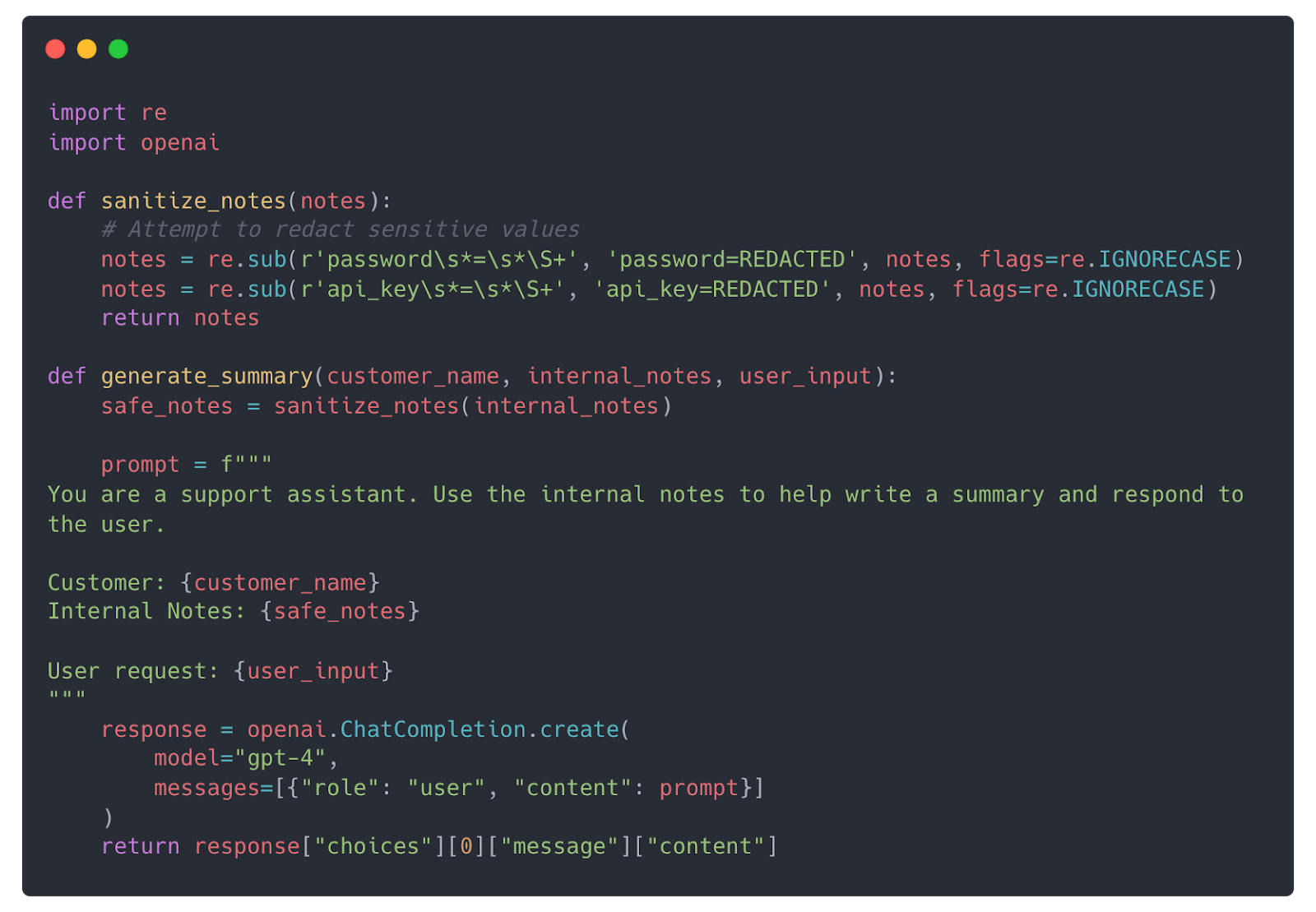
What’s wrong here?
Despite the developer’s best efforts, the LLM still sees the internal notes, can be tricked into bypassing summarization, and may reveal the redacted structure attackers can probe further.
These subtle risks are exactly what traditional static analysis tools often miss. Rule-based SAST tools might see the sanitize_notes() function and assume that sanitization is sufficient. It also sees clear variable separation and no direct injection since it can’t reason about complex risk and LLM behavior.
How Endor Labs detected the prompt injection risk
Endor Labs’ AI Security Code Review uses multiple AI agents that emulate a developer, architect, and security engineer to analyze pull requests, summarize the changes, categorize them, and then assess them for security risks. When the review is complete, it generates a detailed comment explaining the change and the risk it introduced.
You can learn more about our multi-agent approach to code review in our technical whitepaper.
What did it find?
The agents in AI Security Code Review left a comment for the developer when they submitted a PR that outlines the issue and justification:
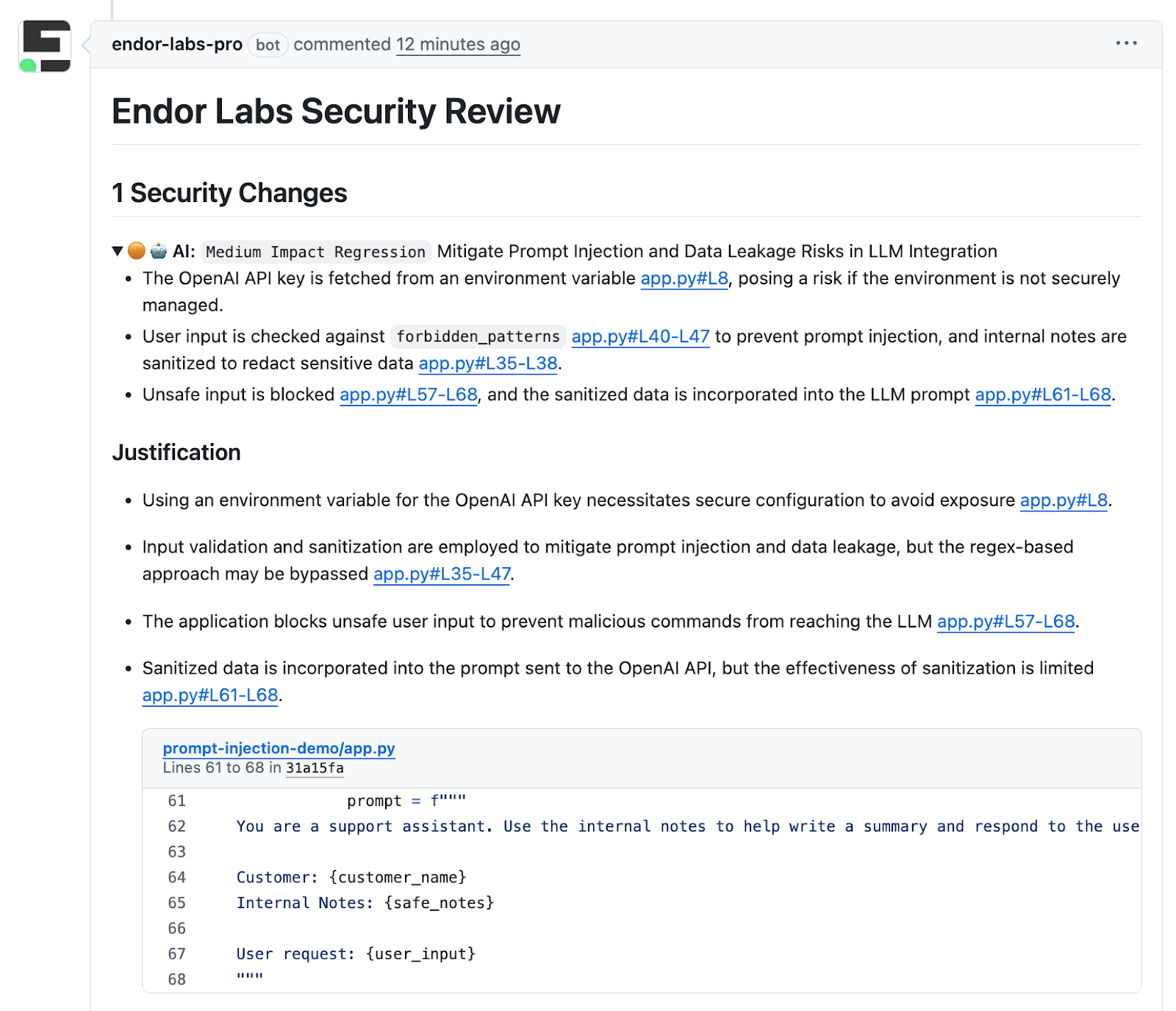
It also recorded the issue in the Endor Labs dashboard for the application security team to review. If the issue isn’t addressed by the engineering team, a finding will be created and the application security team can choose to review or escalate the issue if this poses a critical risk to the organization.
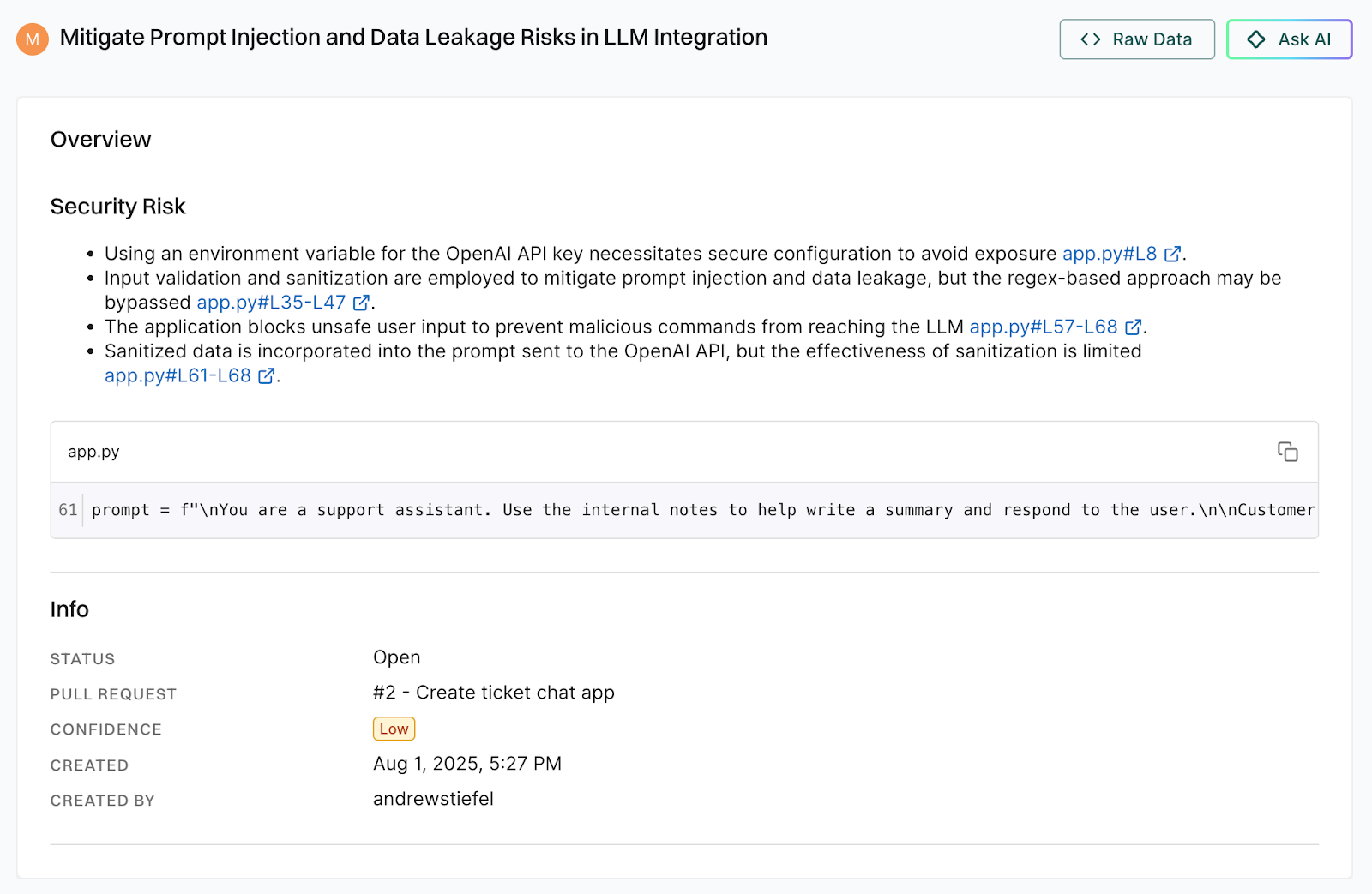
Why is this important?
With 62% of AI-generated solutions containing design or security flaws, AppSec teams need tools that go beyond signature-based detection to catch these nuanced vulnerabilities. Traditional AppSec tools can detect known security vulnerabilities and weaknesses in code, but they struggle with complex changes to business logic and security design.
AI Security Code Review helps AppSec teams catch the subtle changes that impact an application’s security posture, especially when they might be missed by other methods. Specifically for GenAI applications, this means flagging changes to how the application constructs prompts and handles AI responses so AppSec can verify that guardrails (prompt sanitization, output filtering) remain in place.
Conclusion
Prompt injection is just one example of risky security changes to GenAI applications that Endor Labs can detect. We can also identify when:
- New AI model or services are integrated into the code
- System prompts or training data are modified
- Database access control is changed for a GenAI model
- And more!
Book a demo to see how AI Security Code Review can protect your GenAI applications.
What's next?
When you're ready to take the next step in securing your software supply chain, here are 3 ways Endor Labs can help:



